Wednesday, March 29, 2017
Beginning my day with Big off again. So it looks like this machine, which was so far the most stable of all, is acting up. I'm starting to suspect a software issue more than a hardware one, since Muse, Shuttle and Big are all behaving more or less the same way.
Rebooting is stupid
Forced rebooted it. Now my macOS guest is panicking inside. The qcow2 file is reportedly not corrupt, but the guest panicks during fsck. The good thing about VMs is that it's just a matter of copying the disk image from another functioning VM. Just a little waste of time.
Another waste of time is that networking is not working right. Most things work (e.g. I can ssh into the machine or access the web from it), but I don't have VNC access to Big, and macvtap does not work, i.e. none of the guests has netwo rk access. Rebooting. Having to reboot regularly for network issues is really stupid.
Yet another waste of time is that the Bluetooth mouse does not reconnect after boot. Having to connect another mouse for the sake of connecting the Bluetooth mouse every time I have to reboot this machine (which is often) is really stupid.
IO, the file server, is super-super slow. I'm copying my Windows 7 and Windows 8 ISO images to it, it's happening at a mere 11k/s! Apparently, it's the "Hyper Backup" application that causes this, it's sucking I/Os like crazy. Trying to cancel it, but that does not seem to help much. Rebooting. The fact that I have to reboot a file server is really stupid.
Of course, if I ask it to reboot, it won't. It just shuts down all useful services, then sits there forever, so I have to force power it off. After that, I went from 11kb/s to 11Mb/s. What's a mere 1000x between friends?
Oh, and what gets me stuck is the backup application. So I looked at it. And apparently, it's shows a nice green light, but has been unsuccessful backing up anything since March 10 for the "versioned incremental backup", and since March 1 for the "Copy to other volume". Great!
But it's not just Linux. Yesterday, my Mac was acting up, half of the window having network access, the other half complaining about DNS errors. This happened right after I lost connectivity to the Red Hat VPN. I suspect the VPN is messing up badly with DNS resolution (I chose "split DNS", but still). I implemented a small flushdns script, which often gets me out of these situations, but sometimes does not. Yesterday, it did not. I suspect it has to do with Mail.app opening files but never closing them. I'm restarting it regularly, hoping to minimize the problem. Having to reboot because your mail application opens more than 1200 files is really stupid.
Venting a bit of frustration here, but it's already 10:45AM, I've been looking at my systems since about 6:30 this morning, and so far, I've achieved exactly nothing. This is extremely frustrating.
Big is down again
Big went down again, with I/O errors again. And when it came back up, no VNC access. It's clearly a firewall issue, because if I do a remote-viewer vnc://localhost:5900, it works, but if I do remote-viewer vnc://big:5900 from Muse, it doesn't.
Of course, the "solution" I found on the 24th (rebooting the host) did not work this time. Looked at the Firewall application, nothing obvious. Switched the firewall configuration on all network interfaces, nothing. Restarted systemctl restart firewalld, nothing either.
What is infuriating is that I can't VNC to the host, but I can VNC to its guests! Too bad this is exactly not what I need right now!
After scratching my head for a while, I think I figured it out. What happened is the following:
- I noticed bad sectors on one machine. That was actually Big
- I purchased a 3TB replacement disk, but did not install it right away, because I did not want to gut my system open.
- After a while, one of my disk reported BTRFS errors. It was actually Muse, and probably because the disk was really full due to a runaway disk image conversion. But this confused me.
- So I installed the 3TB disk in Muse, and thinking that the 1TB disk was bad, I copied stuff over from the disk in Big. The bad one.
- So now, I most likely had one bad disk in Big, and one good disk in Muse full of data copied over from the bad disk.
I just ran SMART self-tests on all these disks to confirm my hypothesis, and indeed, the disk in Big is bad:
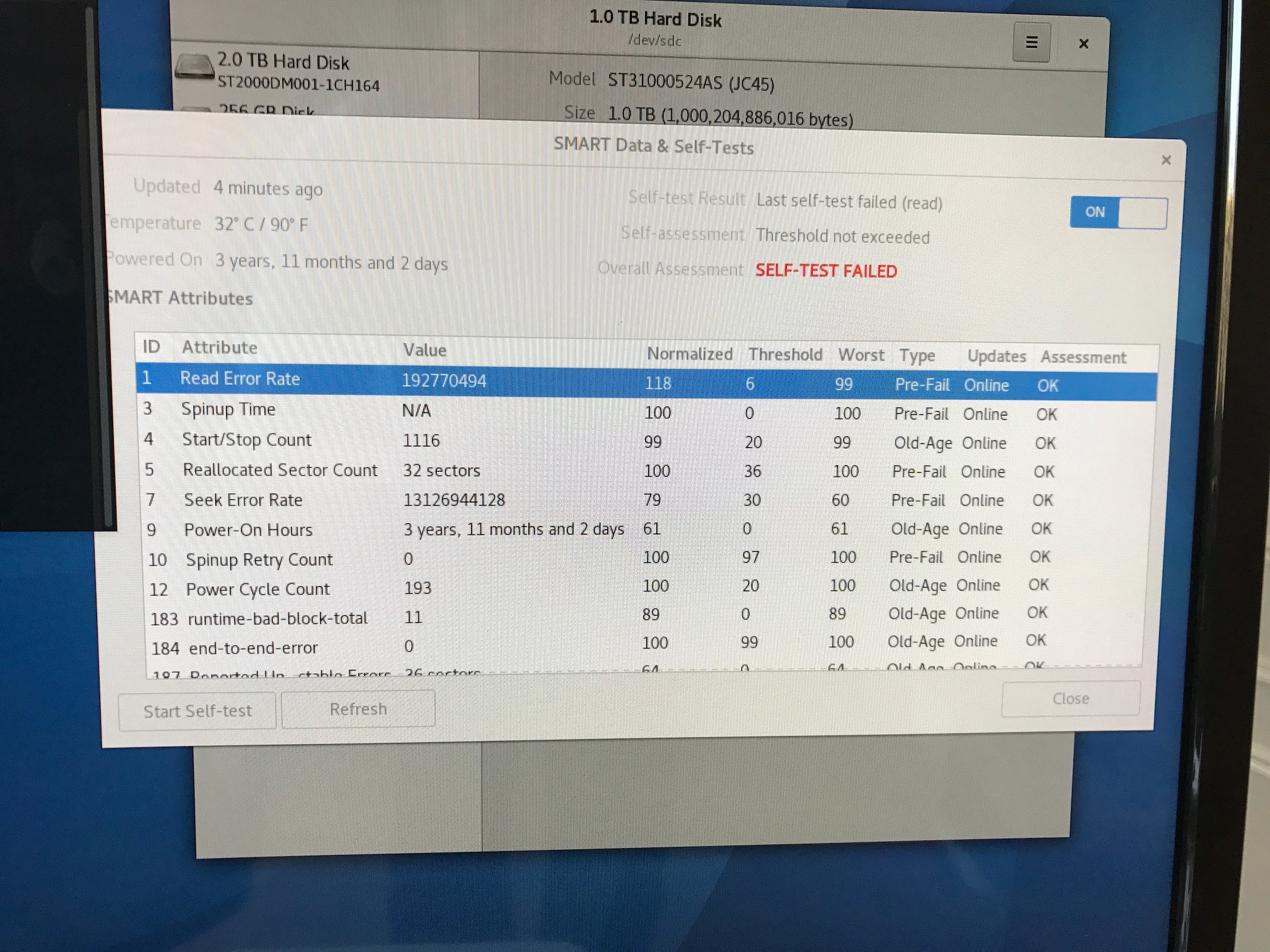
So time to shutdown everyone, swap the disks to have one good disk in each server, and copy data around again.

 2016-2017 - Christophe de Dinechin
2016-2017 - Christophe de Dinechin